✔ 개념
특정 컬럼의 값을 빠르게 찾을 수 있도록 만들어진 검색용 구조
데이터 검색 속도 향상, 중복 방지, 데이터 정렬 등의 성능을 향상시킨다.
✔ Primary Key와 Foreign Key에 기본 인덱스가 설정되는 이유
Primary Key
특징 : 테이블의 각 행을 고유하게 식별하는데 사용
인덱스가 기본 생성되는 이유 : Primary Key는 고유성과 빠른 검색을 보장해야 하므로 인덱스가 필수적.
Foreign Key
특징: 다른 테이블의 Primary Key를 참조하여 두 테이블 간 관계 정의
인덱스가 기본 생성되는 이유 : 종종 다른 테이블과의 조인을 수행하기 때문에 조인 연산의 성능을 높이기 위해 인덱스 생성
✔ 설정방법
--인덱스 설정 기본
CREATE INDEX idx_column_name ON table_name(column_name);
Primary key와 foreign key를 설정할 때 인덱스는 자동으로 생성됩니다.
--primary key 생성
ALTER TABLE table_name ADD PRIMARY KEY (column_name);
✔ 설정의 좋은 예시
빈번한 조회가 발생하는 컬럼
대규모 데이터 정렬이 필요한 경우
자주 조인되는 컬럼
✔ 인덱스의 자료구조
1. 해시 테이블
해시 테이블은 key 와 hash value 쌍으로 이루어진 자료구조이다. 키를 해시함수를 사용하여 해시 값으로 변환 후, 해당 해시 값을 찾아서 검색한다.
2. B-tree
B-Tree 는 자녀 노드의 최대 개수를 늘리기 위해서 부모 노드에 key를 1개 이상 저장하는 자료. B-Tree는 최상위에 단 하나의 노드만이 존재하는데, 이를 루트노드라고 한다. 그리고 중간 노드를 브랜치 노드, 최하위 노드를 리프 노드라고 한다.

노드에는 2개 이상의 데이터(key)가 들어갈 수 있으며, 항상 정렬된 상태로 저장된다

B-Tree의 장점은 '어떤 값에 대해서도 같은 시간에 결과를 얻을 수 있다' 라는 균일성이다. 루트로부터 리프까지의 거리가 일정한 트리를 뜻하는 '균형 트리' 구조를 하고있다.
3. B+tree
B-Tree의 확장개념으로, B-Tree의 경우, branch노드에 key와 data를 담을 수 있다. 하지만 B+Tree의 경우 브랜치 노드에 key만 담아두고, data를 담지 않는다. 오직 리프노드에만 key와 data를 저장하고 리프노드끼리는 linked list로 연결되어있다.

✔ 인덱스의 장단점
장점
- 검색 속도 향상 : 전체 데이터를 스캔하지 않고 원하는 결과를 빠르게 반환 가능
- 정렬된 데이터 접근 용이 : 데이터를 정렬된 상태로 유지하여 ORDER BY 절의 사용이 많은 쿼리에서 성능 향상을 가져올 수 있음
- 데이터 집합 연산 최적화 : JOIN이나 UNION연산을 효율적으로 할 수 있도록 도와줌
단점
- 스토리지 공간 요구 : 인덱스는 데이터의 복사본을 만드느 ㄴ것이므로 추가적인 디스크 공간 소모
- 데이터 변형에 따른 오버헤드 : 데이터 추가,수정,삭제되는 경우 인덱스도 함께 업데이트 되어야함. 데이터를 변경하는 작업에 오버헤드를 추가하게 되므로 이를 항상 고려해야함
- 인덱스 선택과 관리의 복잡성 : 너무 많은 인덱스는 DBMS의 성능 저하, 또한 인덱스의 선택이 DBA의 역할에 중요함
✔ 다중 컬럼 인덱스와 커버링 인덱스 활용
다중 컬럼 인덱스
- 2개 이상의 컬럼으로 이루어진 인덱스
- 인덱스가 구성된 순서에 영향을 받으며, 인덱스가 A,B,C순일때 A에 의해 B가 정렬되며 C도 A,B정렬에 영향을 받아서 순서가 결정된다. 컬럼 순서가 선행하는 인덱스 순서와 동일해야 사용이 가능
커버링 인덱스
- 쿼리를 충족시키는데 필요한 모든 데이터를 가지고 있는 인덱스를 커버링 인덱스라고 한다.
- B-Tree 인덱스를 스캔하는 것만으로도 원하는 데이터를 가져올 수 있으며, 컬럼을 읽기 위해 디스크에 접근하여 데이터 블록을 읽지 않아도 됨.
- 인덱스는 행 전체의 크기보다 훨씬 작다. 디스크에 접근하지 않고도 검색하고자 하는 row의 인덱스를 추출할 수 있다.
✔ 실행 계획과 쿼리 힌트 활용
실행계획이란 사용자가 sql을 실행하여 데이터를 추출하려고 할 때 옵티마이저가 수립하는 절차. 쿼리문의 실행계획을 확인하는 방법은 EXPLAIN ANALYZE, EXPLAIN이 있다.
EXPLAIN (ANALYZE, VERBOSE, BUFFERS, TIMING) (
-- 확인하기 위한 쿼리
SELECT * FROM purchase WHERE count > 5;
)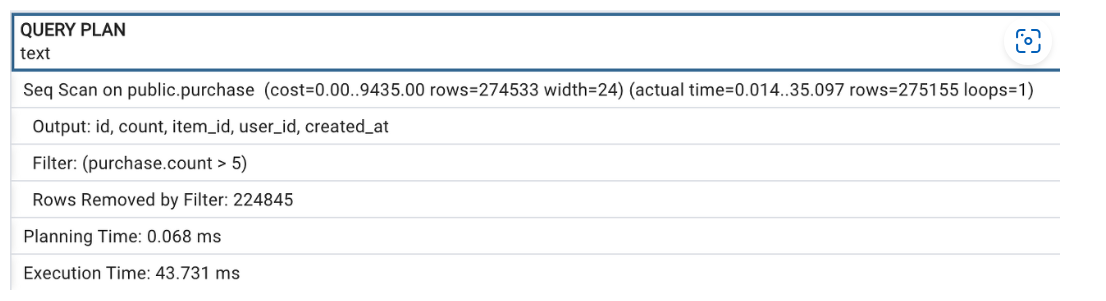
읽는법
- 실행 계획은 각 작업을 노드로 표현한 그래프 형태로 나타나며, 특정 노드는 하위 노드를 포함할 수 있고 노드 간 뎁스는 화살표로 표현된다.
- 같은 뎁스의 작업 간에는 위에서부터 실행되고, 뎁스가 다를 경우엔 더 깊은 노드의 작업이 먼저 실행된다.
- 각 노드 하위에는 해당 작업에 대한 추가적인 설명이 포함된다. (위 예시 기준 Output, Filter 등)
쿼리 힌트 활용
쿼리에서 특정 실행 계획을 지정하도록 하는 명령어. 권장사항정도라고 생각
| MAX_EXECUTION_TIME | 쿼리의 실행 시간 제한 | 글로벌 |
| RESOURCE_GROUP | 쿼리 실행의 리소스 그룹 설정 | 글로벌 |
| SET_VAR | 쿼리 실행을 위한 시스템 변수 제어 | 글로벌 |
| SUBQUERY | 서비쿼리의 세미 조인 최적화 | 쿼리블록 |
| [NO_]BKA | BKA 조인 사용 여부 제어 | 쿼리블록, 테이블 |
| [NO_]BNL | 블록 네스티드 루프 조인, 해시 조인 사용여부 제어 | 쿼리블록, 테이블 |
| [NO_]DERIVED_CONDITION_PUSHDOWN | 외부 쿼리를 서브쿼리로 옮기는 최적화 사용 여부 제어 | 쿼리블록, 테이블 |
| [NO_]HASH_JOIN | 8.0.18 버전만 해시 조인 사용여부 제어 | 쿼리블록, 테이블 |
| JOIN_FIXED_ORDER | FROM절에 명시된 테이블 순서대로 조인 실행 | 쿼리블록 |
| JOIN_ORDER | 힌트에 명시된 테이블 순서대로 조인 실행 | 쿼리블록 |
| JOIN_PREFIX | 힌트에 명시된 테이블을 조인의 드라이빙 테이블로 조인 실행 | 쿼리블록 |
| JOIN_SUFFIX | 힌트에 명시된 테이블을 조인의 드리븐 테이블로 조인 실행 | 쿼리블록 |
| QB_NAME | 쿼리 블록의 이름 설정을 위한 힌트 | 쿼리블록 |
| [NO_]SEMIJOIN | 서브 쿼리의 세미 조인 최적화 전략 제어 | 쿼리블록 |
| [NO_]MERGE | FROM 절의 서브쿼리나 뷰를 외부 쿼리 블록으로 병합하는 최적화 사용 여부 제어 | 테이블 |
| [NO_]INDEX_MERGE | 인덱스 병합 실행계획 사용 여부 제어 | 테이블, 인덱스 |
| [NO_]MRR | MRR(Multi Range Read) 사용 여부 제어 | 테이블, 인덱스 |
| NO_ICP | 인덱스 컨디션 푸시다운 최적화 사용 여부 제어 | 테이블, 인덱스 |
| NO_RANGE_OPTIMIZATION | 인덱스 레인지 액세스를 비활성화 | 테이블, 인덱스 |
| [NO_]SKIP_SCAN | 인덱스 스킵 스캔 사용 여부 제어 | 테이블, 인덱스 |
| [NO_]INDEX | GROUP BY, ORDER BY, WHERE절의 처리를 위한 인덱스 사용 여부 제어 | 인덱스 |
| [NO_]GROUP_INDEX | GROUP BY 절의 처리를 위한 인덱스 사용여부 제어 | 인덱스 |
| [NO_]JOIN_INDEX | WHERE 절의 처리를 위한 인덱스 사용여부 제어 | 인덱스 |
| [NO_]ORDER_INDEX | ORDER BY 절의 처리를 위한 인덱스 사용여부 제어 | 인덱스 |
✔ 인덱스 최적화와 주의사항
1. 쿼리 실행 계획 분석 및 최적화
쿼리 실행 계획은 데이터베이스가 쿼리를 어떻게 실행할지 결정하는 정보입니다.
이를 분석하고 최적화하여 쿼리의 실행 속도를 향상시킬 수 있습니다.
쿼리 실행 계획은 EXPLAIN 명령을 사용하여 확인할 수 있습니다. 실행 계획을 분석하여 인덱스가 적절히 활용되고 있는지, 테이블 스캔이 필요한 부분은 없는지 등을 확인해야 합니다.
필요한 경우 인덱스를 추가하거나 기존 인덱스를 수정하여 쿼리 실행 계획을 최적화할 수 있습니다.
2. 인덱스 통계 정보 활용 방법
인덱스 통계 정보는 데이터베이스가 인덱스를 선택하고 사용하는 데 도움을 줍니다. 이를 통해 쿼리 옵티마이저는 최적의 실행 계획을 수립할 수 있습니다.
MySQL에서는 ANALYZE TABLE 명령을 사용하여 테이블의 인덱스 통계 정보를 수집할 수 있습니다. 이를 통해 인덱스의 선택도(카디널리티)와 분포도를 확인할 수 있습니다.
인덱스 통계 정보를 정기적으로 업데이트하고 관리하여 최신 정보를 유지해야 합니다. 데이터의 분포가 변경되었을 때는 통계 정보를 업데이트해야 합니다.
참고자
[MySQL] B-Tree로 인덱스(Index)에 대해 쉽고 완벽하게 이해하기 - MangKyu's Diary
[MySQL] B-Tree로 인덱스(Index)에 대해 쉽고 완벽하게 이해하기
인덱스를 저장하는 방식(또는 알고리즘)에 따라 B-Tree 인덱스, Hash 인덱스, Fractal 인덱스 등으로 나눌 수 있습니다. 일반적으로 B-Tree 구조가 사용되기 때문에 B-Tree 인덱스를 통해 인덱스의 동작
mangkyu.tistory.com
[자료구조] 그림으로 알아보는 B-Tree
B트리는 이진트리에서 발전되어 모든 리프노드들이 같은 레벨을 가질 수 있도록 자동으로 벨런스를 맞추는 트리입니다.
velog.io
https://yelkim0210.tistory.com/159
'데이터베이스' 카테고리의 다른 글
| [DB] SQL (0) | 2025.04.13 |
|---|---|
| [DB] 데이터조회 _ SELECT (0) | 2025.04.12 |
| [DB] SQL의 개념 (0) | 2025.04.11 |
| [DB] 데이터베이스란? (0) | 2025.04.03 |



